Case of sudden Kafka lag drop
Recently we faced an interesting issue in our data pipeline where we observed Kafka consumer lag suddenly dropping whenever it reached a certain threshold. This behavior was unexpected and potentially concerning, as consumer lag—the difference between the latest message produced and the message currently being processed by consumers—should typically decrease gradually as consumers process messages.
The Problem
Our application was relatively simple, with two instances of pods running in Kubernetes. Since we didn’t need high throughput, the Kafka topic had only a single partition. The screenshot below shows the behavior we observed.
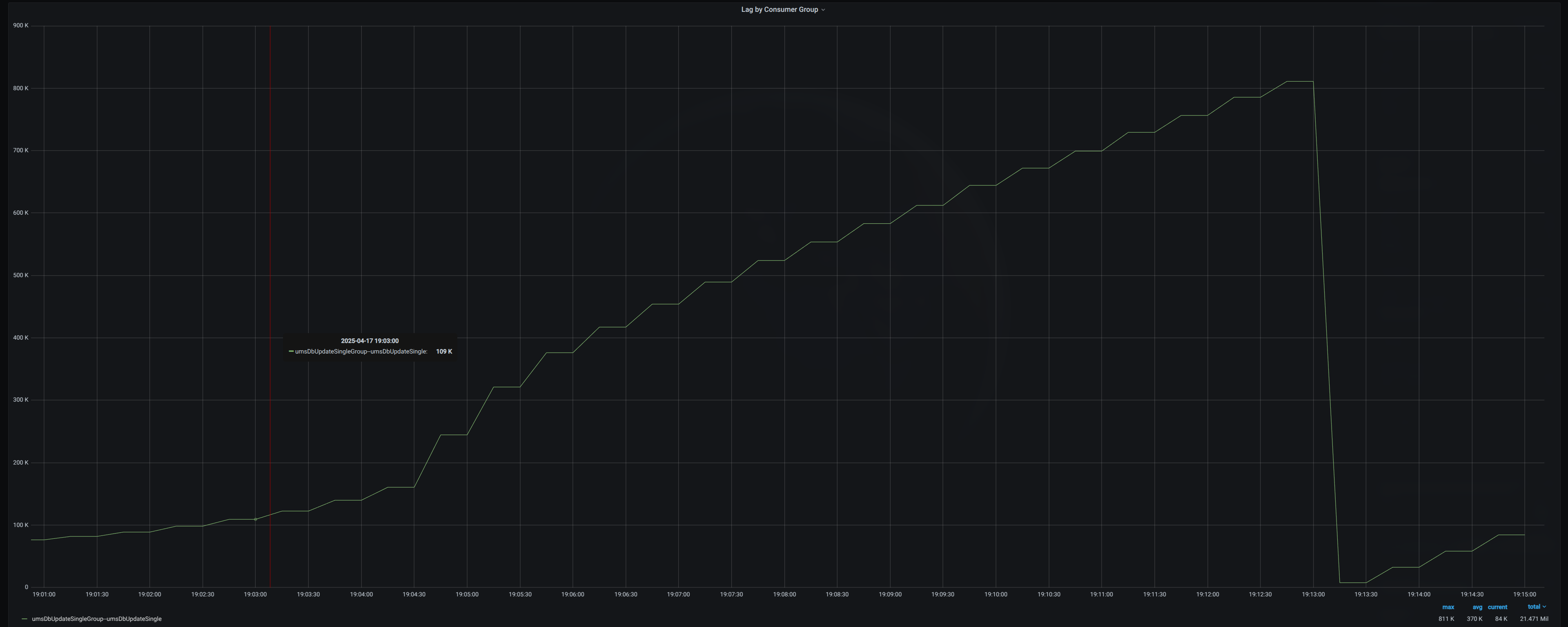
As visible in the graph, the consumer lag would build up gradually but then suddenly drop at certain points, creating a sawtooth pattern rather than the expected gradual decline.
Investigation
When facing such an issue with Kafka lag abruptly dropping, one of the first things to check is the retention.bytes setting of the topic and its partitions. It’s possible that when a topic reaches its retention.bytes capacity, Kafka will start deleting the oldest log segment files. The size of these segment files is defined by the segment.bytes property. To inspect our topic’s configuration, we ran:
./kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic single_partition_topic --describe
Topic: single_partition_topic TopicId: tNA9_CAwT62MzHsW88b_Ig PartitionCount: 1 ReplicationFactor: 2 Configs: segment.bytes=104857600,retention.bytes=173741824
Topic: single_partition_topic Partition: 0 Leader: 1 Replicas: 1,3 Isr: 1,3
Root Cause Analysis
The output revealed that our topic had:
- A retention.bytes of 173MB
- A segment.bytes of approximately 100MB
This configuration meant that for this topic, the Kafka server could maintain at most two segment log files:
- The first segment file (up to 100MB)
- A second segment file (which could only grow to about 73MB before hitting the total retention limit)
When the second file would reach around 73MB, Kafka would be forced to delete the first file entirely to stay within the retention limit. This deletion caused the earliest available offset in the topic to jump forward, resulting in the abrupt consumer lag drop we were observing. This problem is particularly likely to occur with topics that have a low number of partitions, since the retention.bytes setting is applied at the partition level, not at the topic level.
Solution
The solution was straightforward: increase the retention.bytes property of the topic to allow for more data retention. We executed:
./kafka-configs.sh --bootstrap-server localhost:9092 --entity-type topics --entity-name single_partition_topic --alter --add-config retention.bytes=1073741824
With this command, we increased the retention.bytes property from 173MB to 1073MB (approximately 1GB), which solved our problem by allowing more headroom for message retention.
To verify that the setting was applied correctly, we ran:
./kafka-configs.sh --bootstrap-server localhost:9092 --entity-type topics --entity-name single_partition_topic --describe --all
All configs for topic single_partition_topic are:
compression.type=producer sensitive=false synonyms={DEFAULT_CONFIG:compression.type=producer}
leader.replication.throttled.replicas= sensitive=false synonyms={}
message.downconversion.enable=true sensitive=false synonyms={DEFAULT_CONFIG:log.message.downconversion.enable=true}
min.insync.replicas=1 sensitive=false synonyms={DEFAULT_CONFIG:min.insync.replicas=1}
segment.jitter.ms=0 sensitive=false synonyms={}
cleanup.policy=delete sensitive=false synonyms={DEFAULT_CONFIG:log.cleanup.policy=delete}
flush.ms=9223372036854775807 sensitive=false synonyms={}
follower.replication.throttled.replicas= sensitive=false synonyms={}
segment.bytes=104857600 sensitive=false synonyms={STATIC_BROKER_CONFIG:log.segment.bytes=104857600, DEFAULT_CONFIG:log.segment.bytes=1073741824}
retention.ms=86400000 sensitive=false synonyms={}
flush.messages=9223372036854775807 sensitive=false synonyms={DEFAULT_CONFIG:log.flush.interval.messages=9223372036854775807}
message.format.version=2.8-IV1 sensitive=false synonyms={DEFAULT_CONFIG:log.message.format.version=2.8-IV1}
max.compaction.lag.ms=9223372036854775807 sensitive=false synonyms={DEFAULT_CONFIG:log.cleaner.max.compaction.lag.ms=9223372036854775807}
file.delete.delay.ms=60000 sensitive=false synonyms={DEFAULT_CONFIG:log.segment.delete.delay.ms=60000}
max.message.bytes=1048588 sensitive=false synonyms={DEFAULT_CONFIG:message.max.bytes=1048588}
min.compaction.lag.ms=0 sensitive=false synonyms={DEFAULT_CONFIG:log.cleaner.min.compaction.lag.ms=0}
message.timestamp.type=CreateTime sensitive=false synonyms={DEFAULT_CONFIG:log.message.timestamp.type=CreateTime}
preallocate=false sensitive=false synonyms={DEFAULT_CONFIG:log.preallocate=false}
min.cleanable.dirty.ratio=0.5 sensitive=false synonyms={DEFAULT_CONFIG:log.cleaner.min.cleanable.ratio=0.5}
index.interval.bytes=4096 sensitive=false synonyms={DEFAULT_CONFIG:log.index.interval.bytes=4096}
unclean.leader.election.enable=false sensitive=false synonyms={DEFAULT_CONFIG:unclean.leader.election.enable=false}
retention.bytes=1073741824 sensitive=false synonyms={DYNAMIC_TOPIC_CONFIG:retention.bytes=1073741824, STATIC_BROKER_CONFIG:log.retention.bytes=173741824, DEFAULT_CONFIG:log.retention.bytes=-1}
delete.retention.ms=86400000 sensitive=false synonyms={DEFAULT_CONFIG:log.cleaner.delete.retention.ms=86400000}
segment.ms=604800000 sensitive=false synonyms={}
message.timestamp.difference.max.ms=9223372036854775807 sensitive=false synonyms={DEFAULT_CONFIG:log.message.timestamp.difference.max.ms=9223372036854775807}
segment.index.bytes=10485760 sensitive=false synonyms={DEFAULT_CONFIG:log.index.size.max.bytes=10485760}
This command will show all configurations for the topic with a DEFAULT or DYNAMIC source column, where:
- DYNAMIC means the configuration was explicitly set for this specific topic
- DEFAULT means the configuration is inherited from the broker-level defaults
In the output (partially shown below), we could confirm the change was successful:
retention.bytes=1073741824 sensitive=false synonyms={DYNAMIC_TOPIC_CONFIG:retention.bytes=1073741824, STATIC_BROKER_CONFIG:log.retention.bytes=173741824, DEFAULT_CONFIG:log.retention.bytes=-1}
The presence of DYNAMIC_TOPIC_CONFIG:retention.bytes=1073741824 indicates that our topic-level override was successfully applied.
Best Practices and Additional Considerations
When configuring Kafka topics, keep these points in mind:
- Balance retention settings: Remember that both retention.bytes and retention.ms (time-based retention) can trigger log segment deletion. Configure both appropriately for your use case.
- Monitor partition growth: For topics with few partitions, monitor data growth closely and set retention limits accordingly.
- Consider partition count: If you need to retain more data and scaling consumption throughput is desirable, consider increasing the partition count.
- Check broker defaults: The default retention settings are defined in the Kafka broker’s server.properties file under log.retention.bytes and log.retention.hours. Be aware of these defaults when creating new topics.
Conclusion
Sudden drops in Kafka consumer lag can often be traced back to retention settings causing older messages to be deleted. By understanding how retention.bytes and segment.bytes interact, particularly at the partition level, you can properly size these settings to match your data retention needs.
If you’re seeing unexpected behavior in your Kafka metrics, checking these configuration parameters should be one of your first troubleshooting steps.